Intel Developer Forum Fall 2002 - Hyper-Threading & Memory Roadmap
by Anand Lal Shimpi on September 16, 2002 6:05 PM EST- Posted in
- Trade Shows
Dinner with Pat: Hyper-Threading over Cocktails
We were fortunate enough to have dinner with Intel's CTO, Pat Gelsinger to pick his brain about technology. Being an engineer at heart, Pat will give you more than enough detail on any aspect of Intel's technologies. We asked him what he felt was the most exciting thing in Intel's current arsenal and he responded with a simple "threading."
In reference to Hyper-Threading, Pat explained exactly why this is very important to the future of Intel microprocessors. For the past decade or so the focus of Intel's microprocessor architects have been on extracting instruction level parallelism (ILP) or simply put, making sure that the CPU could execute as many instructions as possible in parallel. Today, the limits of ILP engineering are kicking in and both AMD and Intel are noticing diminishing returns from all architectural enhancements aimed at improving the ILP of CPUs. You can optimize your CPU architecture for executing many instructions in parallel but as long as the CPU is not being fed those instructions fast enough your optimizations will be useless; this is why there's such a focus on latency to main memory and memory bandwidth. The faster the CPU-memory link is, the more instructions the CPU can start crunching on which benefit from the ILP optimizations put in these CPUs; unfortunately today's memory subsystems aren't anywhere near as fast as they need to be and thus we are beginning to hit a wall.
Pat admitted that much of Intel's success over the past decade has been due to their fabs and manufacturing capabilities that allowed them to increase cache sizes and implement a good deal of parallel execution units; moving forward however, the challenge lies on Intel to go beyond just manufacturing leadership.
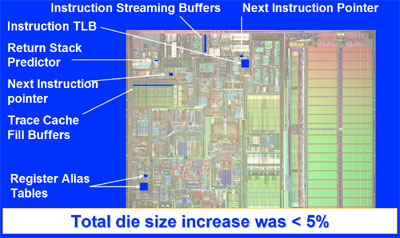
The changes to the Northwood core were minimal to implement Hyper-Threading.
Using the Northwood Pentium 4 core as an example, doubling the cache of a processor ends up increasing performance 5 - 10% across the board in today's applications. This increase in performance comes at an extremely high price however, by increasing the die size tremendously and upping transistor count. Pat mentioned that although Intel may implement an on-die memory controller in future CPUs (ala Hammer) this isn't the only solution to the problem of starving execution units; even with an on-die memory controller there is still a noticeable latency between the CPU and main memory and cache misses result in a number of idle CPU clocks, there are fewer misses but they still exist.
Pat's take on the situation is that if you can't keep the CPU busy with instructions, throw another thread at it and voila, CPU efficiency jumps from ~35% to much closer to 50%. We've explained the reasons for this before but to recap, most current desktop processors can only execute one thread at a time. A thread can be thought of as a collection of instructions that are sent to the CPU to be executed; every application that runs dispatches threads to the CPU to be executed, with each application sending its own threads. If a single CPU could receive two threads simultaneously, the CPU could now receive more instructions to work on and thus keeping its pipeline filled and busy. A single application could send two threads (called a multithreaded application), such as a 3D rendering application; one thread could handle the rendering of even lines while the other thread would render odd numbered lines. You could also have two single threaded applications running simultaneously, like running Microsoft Outlook while encoding a video to MPEG-4. This is exactly what Intel's Hyper-Threading technology enables, and in Q4 it will be coming to the desktop with the 3.06GHz Pentium 4.
But according to Pat, this is just the first step in a very long road for Intel. Including Hyper-Threading only costs about 5% of die space and can improve performance from 0 - 35% in every day applications and scenarios. Intel showed off some very impressive demos of the current version of Hyper-Threading in the 3.06GHz Pentium 4 and most all of our doubts about the technology's feasibility vanished. Performance in today's multitasking scenarios will improve in a very noticeable way, and gains in multithreaded applications are very respectable (DiVX encoding fans will definitely appreciate Hyper-Threading).
The future of Hyper-Threading will assume many different faces, many of which Pat is overseeing research on right now. One of the most interesting areas is in the compiler realm; future versions of Intel compilers may be able to generate support for pseudo-multithreading on their own. As we've described before, pseudo-multithreading involves the creation of helper threads that go further into program execution and speculate on data that will be used in the near future and pulling it into the processor's cache. Assuming that a helper thread correctly pulls something into cache that wouldn't have normally been in cache, performance can be improved considerably as it would've just avoided a cache miss.
Another area for the future of Hyper-Threading is allowing more than two threads to be executed on the CPU simultaneously. Remember that the number of instructions the CPU executes per clock (IPC) can be improved by around 40% by moving to two threads, the theory is that with more threads performance could improve even more. There is one thing to watch out for, performance degradation could result if these threads begin combating for the same resources so more than two threads is still a little while away.
Pat sees Hyper-Threading and a general focus on thread level parallelism (TLP) as the future trend of microprocessor development, at least at Intel. We asked Pat what he thought about AMD's approach and he responded that every day AMD doesn't have Hyper-Threading makes him happier. AMD could take a different approach by moving to affordable multiprocessor designs with future versions of Hammer; remember that with a multiprocessor system you still have the ability to run more than one thread at a time (one thread per CPU x the number of CPUs) thus moving towards a TLP optimized design. With the very low size of AMD cores this may end up being their answer to Intel's Hyper-Threading, although a more expensive route.








0 Comments
View All Comments